文法
G=(VN,VT,P,S)
VN:非终结符(大写) VT:终结符(小写) P:规则集合 S:开始符号
题一
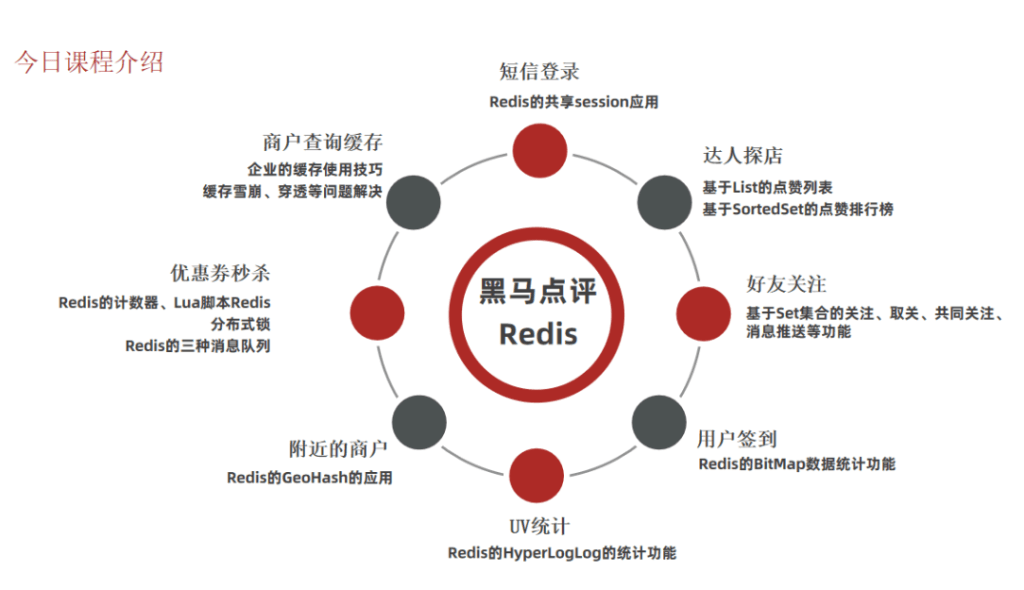
L1={ambn|m,n≥1}
当m=1,n=1 ab m=2,n=1 aab …aabb aabbb
S->AB
A->a|aA
B->b|bB
即VN={S,A,B}, VT={a,b},S=S,
p={S->AB
A->a|aA
B->b|bB}
题二
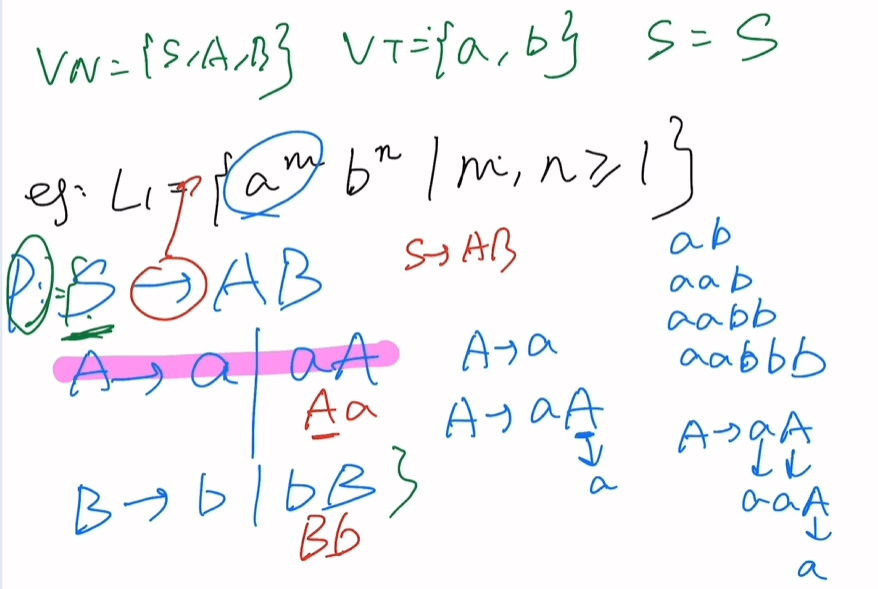
L2={anbnci|n≥1,i≥0}
ab,abc,aabbc,aabbcc
S->AB
A->ab|aAb
B->ε|Bc
即VN={S,A,B}, VT={a,b,c},S=S,
p={S->AB
A->ab|aAb
B->ε|Bc}
题三

题四
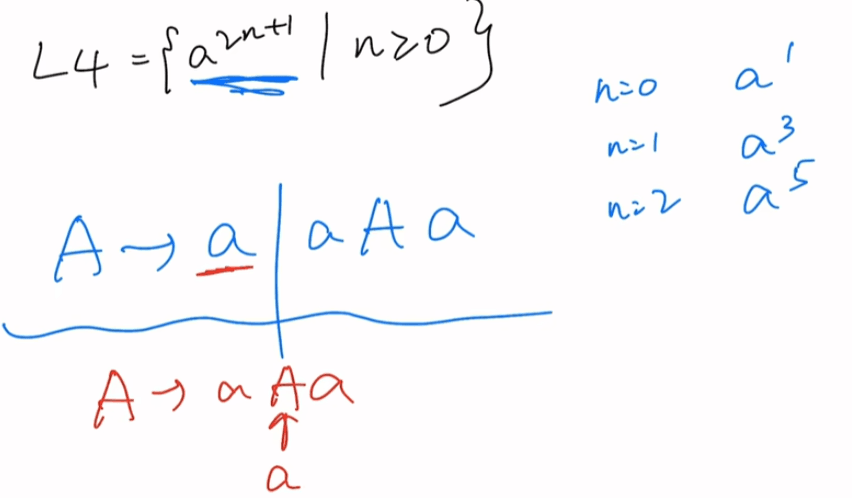
题五

最左推导和最右推导
题一
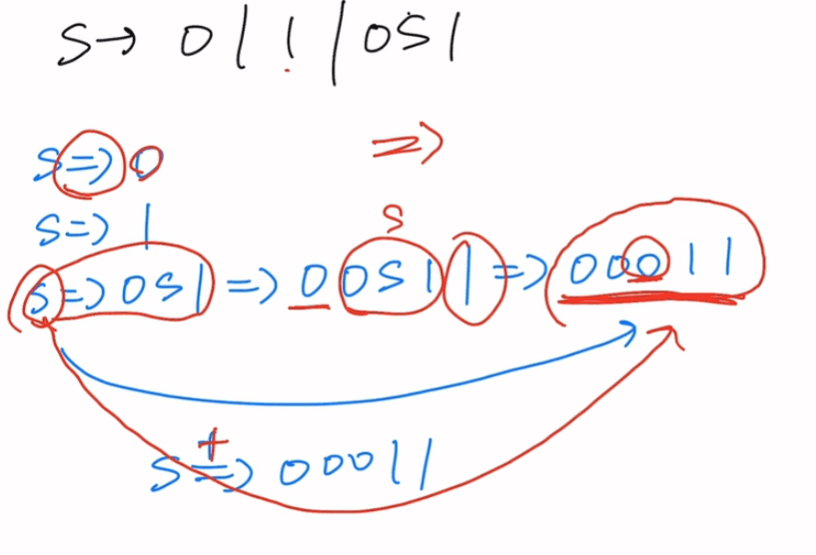
推导箭头带加号,意为广义推导,表示跳过了好几步直接得到最终结果

最左推导:以左边为基准
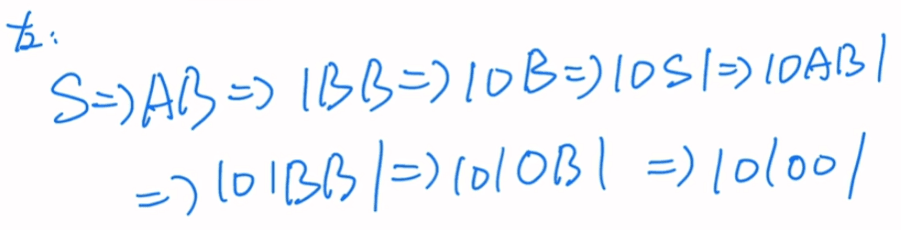
最右推导:以右边为基准
AAB1=> AA01=> A1B01 =>A1001
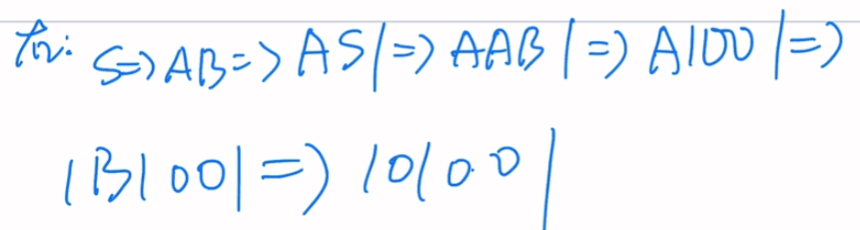
题二
最左推导
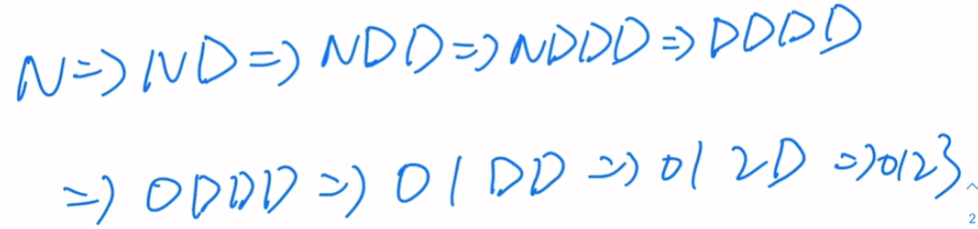
最右推导
N=>ND=>N3=>ND3=>N23=>ND23=>N123=>D123=0123
归约和语法树

文法的二义性与分类

先进行最左最右推导

左推导树与右推导树
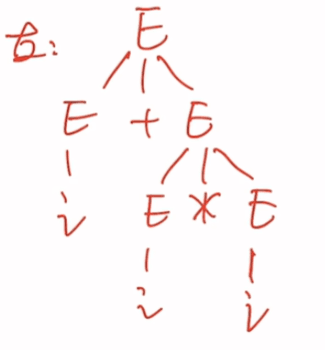

可以发现左右推导树不一样,即二义性
文法分类
0型(无限制文法)
1型(上下文有关)
2型(上下文无关)
3型(正规文法)
0型:
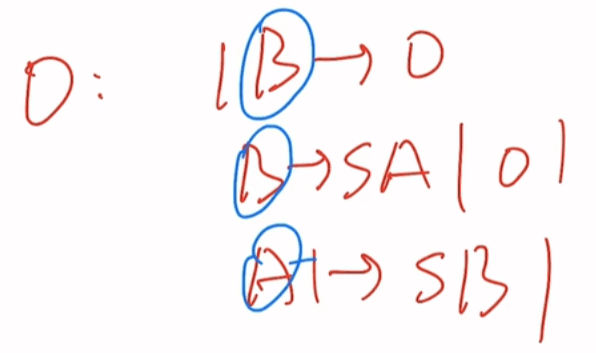
左边至少有一个大写字母(非终结符)
1型:
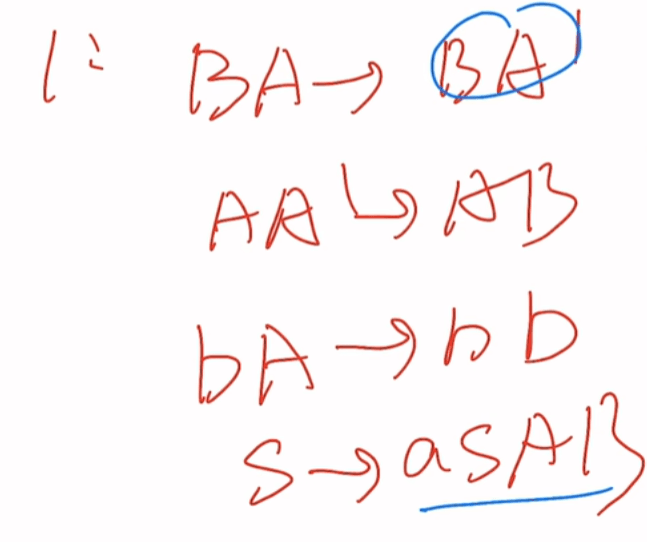
右边长度≥左边长度
2型:
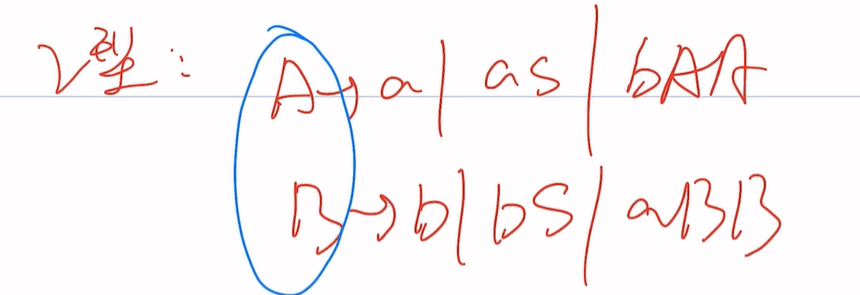
左边只能有一个大写字母(非终结符)
3型:左/右线性文法大概是这个意思:若文法的右边(箭头的右边)有非终结符(大写字母),则这些大写字母必须在所在组合的最左/右边。
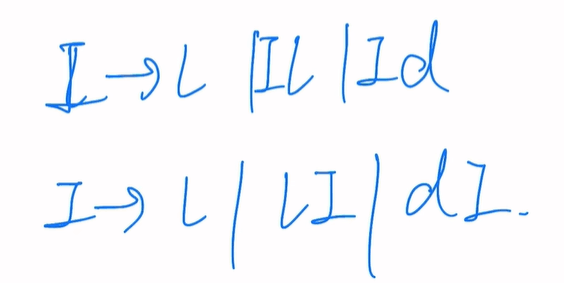
第一行左线性文法
第二行右线性文法
短语直接短语句柄
短语:有子结点的围圈,最边缘
直接短语:一个子结点,围圈高度为2(在短语围的圈里找高度为2的圈)
句柄:最左直接短语
题一
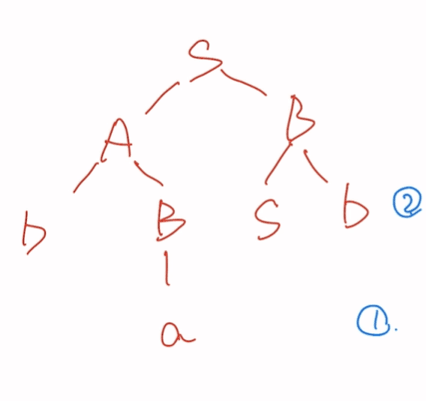
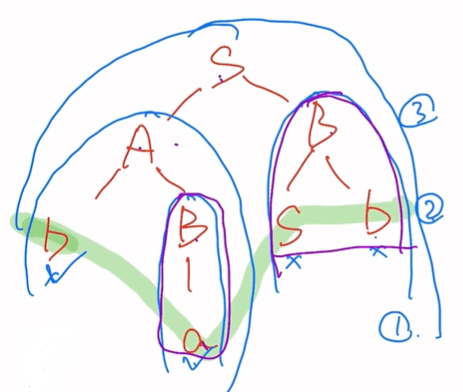
短语:a,ba,sb,basb
直接短语:a,sb
句柄:a
题二

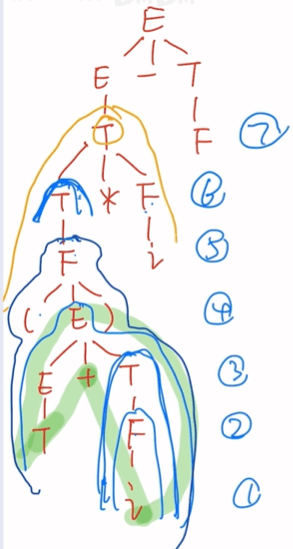
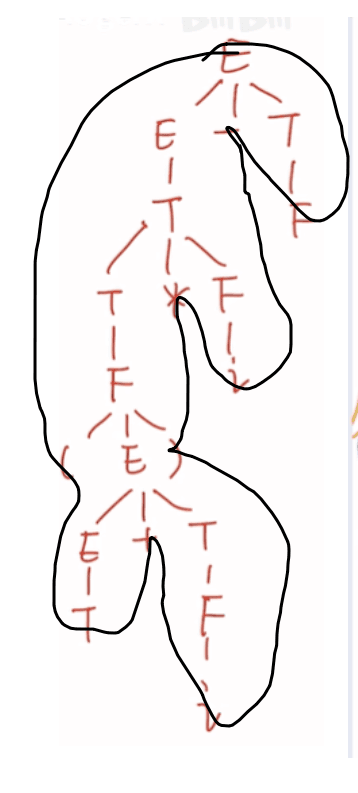
短语:i,T,T+i,(T+i),(T+i)*i,(T+i)*i-F
直接短语:i,F,T
句柄:T
正规式到NFA
什么是正规式?
假设要以b开头,要aa结尾的句子发现有很多情况比如,baa,bbaa,bxxxxaa(xxxx又能取ab的各种组合)
用正规式表达就是(a|b)*
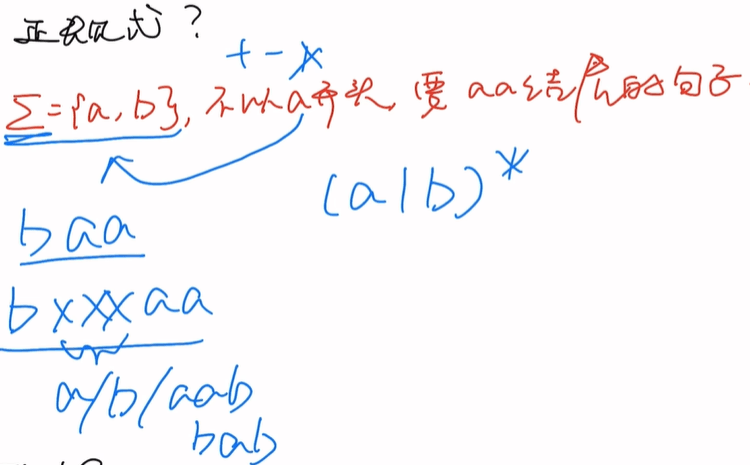
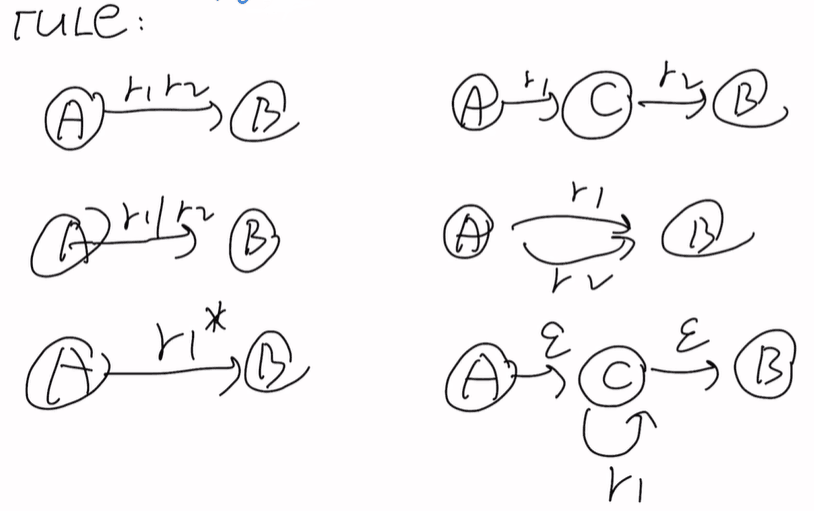
rule规则
题一
(a|b)*为一组abb为一组 开始符号一个圈,末态两个圈
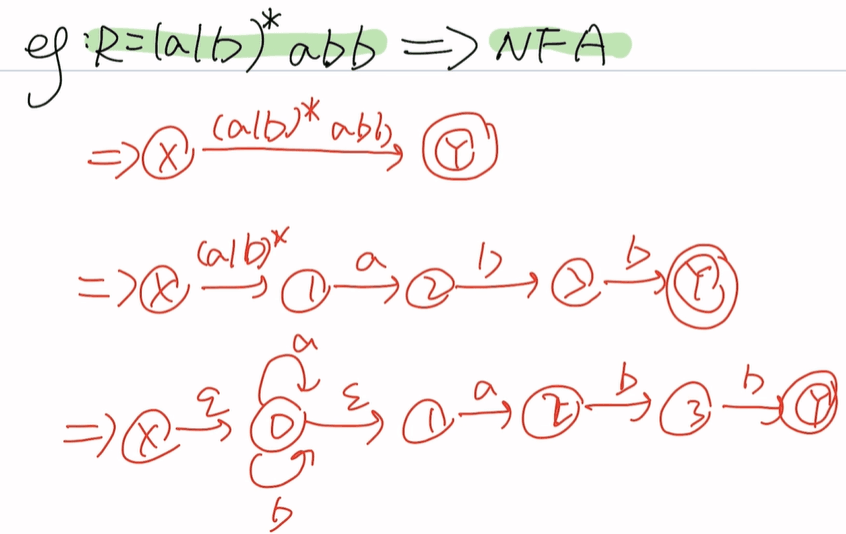
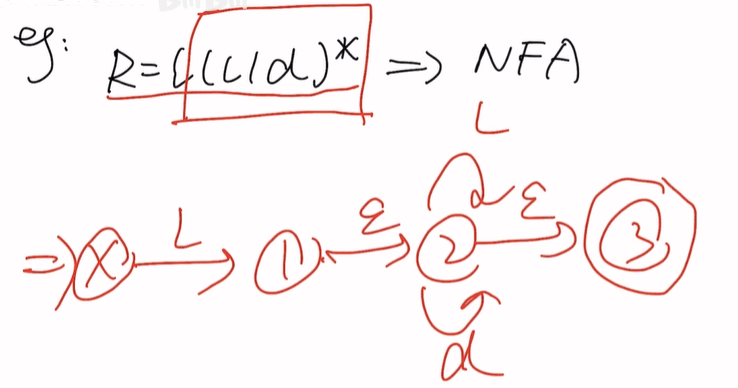
题二
l一组,(l|d)*一组
NFA到DFA(子集法)
NFA怎么转到DFA:子集法
也就是列一个表
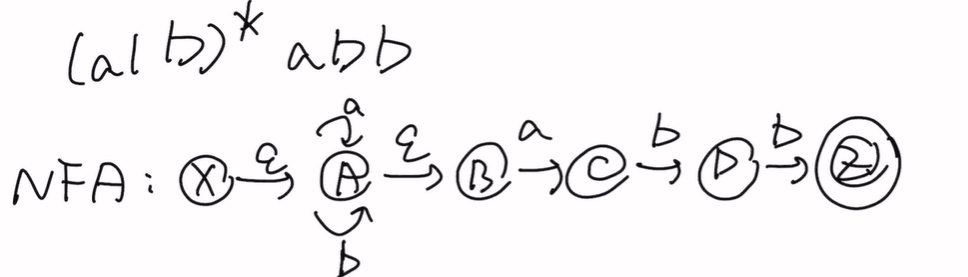
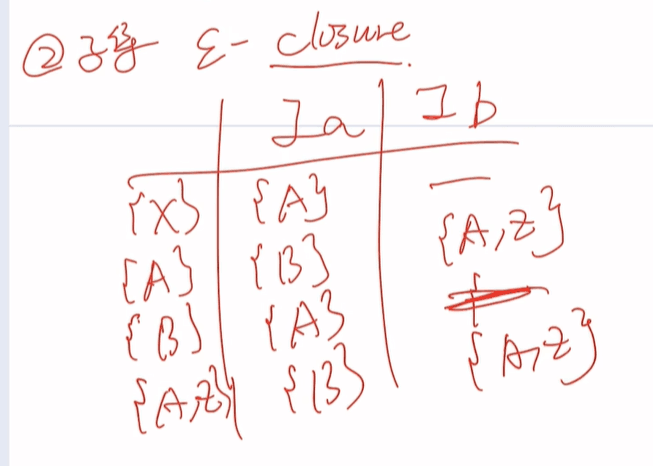
空串可以看做氮气加速,不耗体力前往下一项
初始状态为什么是{X,A,B}:因为X后有空串可以氮气加速到A或者B
{ABC}怎么来的?当给初始状态一个a,对于X:它本身就可以通过氮气到A,又根据第二次氮气到B,之后给a直接到C。对于A:同理先氮气到B,给a直接到C。对应B:给a直接到C
第二个{ABC}怎么来的?当给一个a,对于A:给它一个a本身就能到A,后通过氮气到B。对于B:给a到C。对于C:没有效果
后面的填表跟前面一样,不再阐述
| Ia | Ib | |
| 初始状态{X,A,B} | {A,B,C} | {A,B} |
| 写未探索的{A,B,C} | {A,B,C} | {A,B,D} |
| 写未探索的{A,B} | {A,B,C} | {A,B} |
| 写未探索的{A,B,D} | {A,B,C} | {A,B,Z} |
| 写未探索的{A,B,Z} | {A,B,C} | {A,B} |
由于我们末态是Z,在表中先标出Z的位置,我们给表设置数字,看看右边的数据对应左边的几号如图
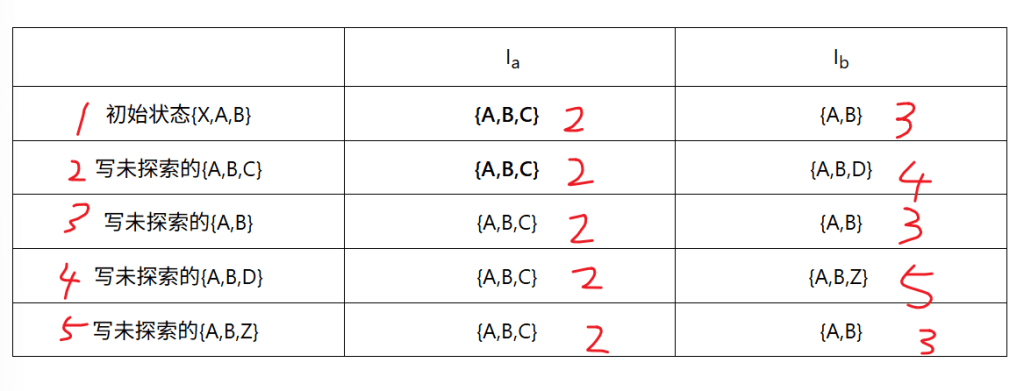
简化一下:
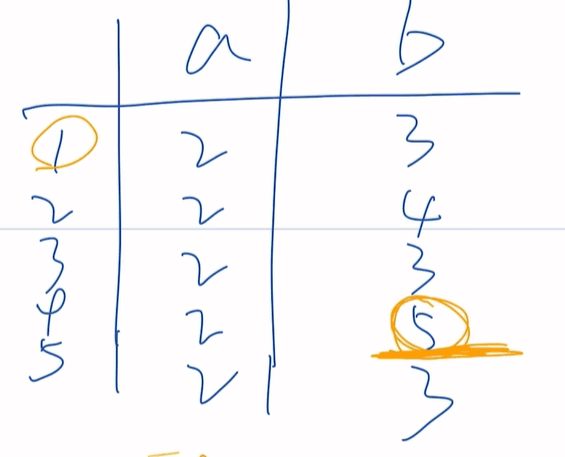
最小化DFA(找IKUN)
分状态,先大分,5末态单独分一组(5末态默认为IKUN)
即{1,2,3,4}{5}
{1,2,3,4}a={2}
{1,2,3,4}b={3,4,5}出现了5,抓住4这个ikun了
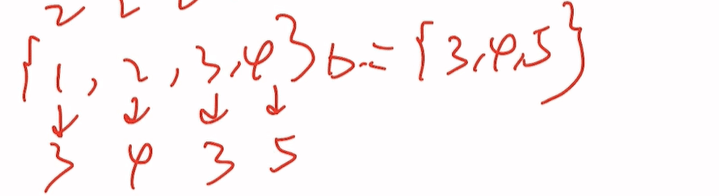
抓到ikun后更新一轮分组
即{1,2,3}{4}{5}
{1,2,3}a={2}
{1,2,3}b={3,4}出现了4,抓住2这个ikun
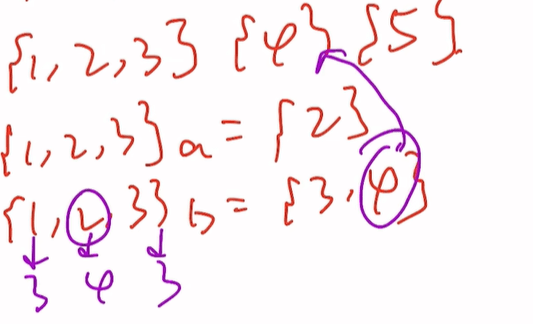
抓到ikun后更新一轮分组
{1,3}{2}{4}{5}
{1,3}a={2}出现了2,{1,3}都是ikun那就不用分了
即最终的状态是:{1,3}{2}{4}{5}
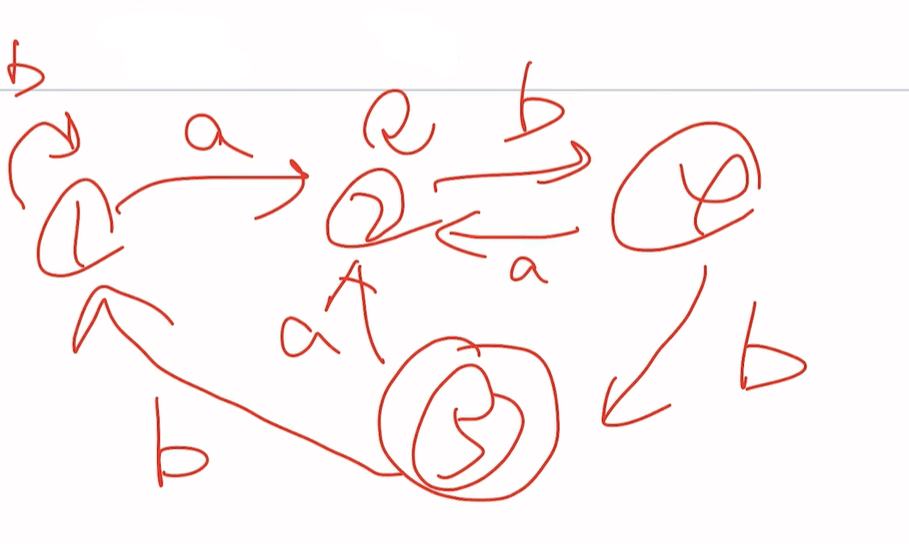
1,3共体只用画一个
这里面12345也可以换成ABCDE都是一样的
正规文法到DFA
首先要了解正规文法->正规式

1为右线性文法 2为左线性文法
题一

注意两个要点 -> 变为 = | 变为 + 即下图
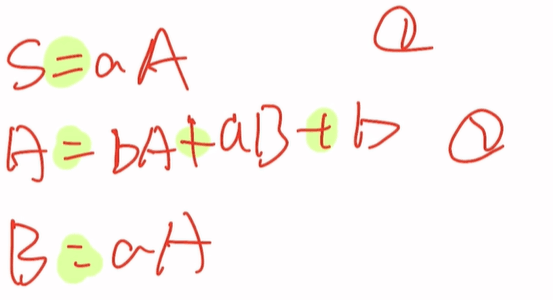
最后要求出正规式即S=( )的形式
带入方程得S=a(b+aa)A+b,发现符合这一条规则

即S=a(b+aa)*b=a(b|aa)*b
正规文法->正规式->NFA->子集法->DFA->最小化DFA

接下来就是正规文法到DFA的过程:我们已经得到了正规式接下先得到NFA再通过子集法得到DFA最后再通过最小化DFA得到最后的结果
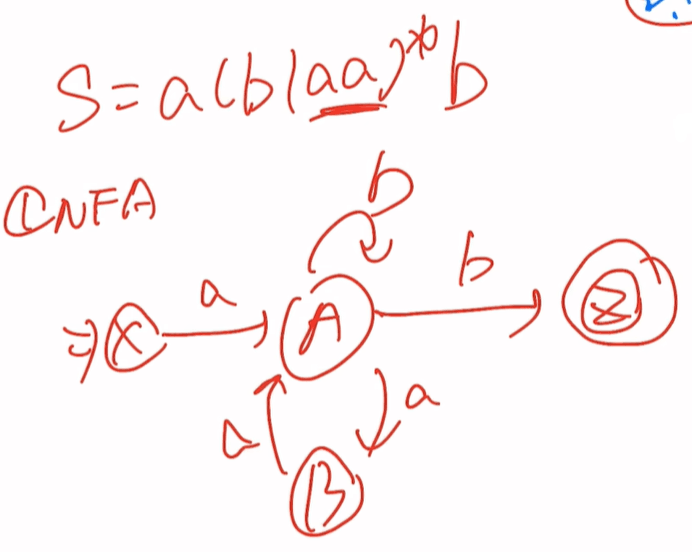
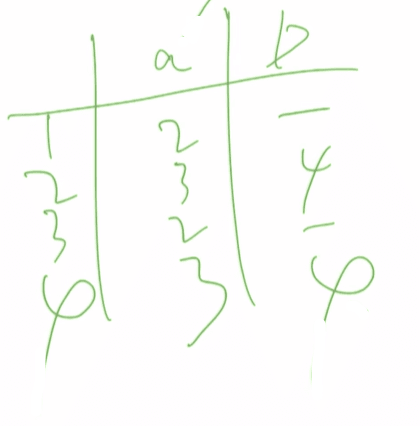
最小化DFA{1,2,3}{4}找小黑子过程略
结果{1,3}{2}{4}
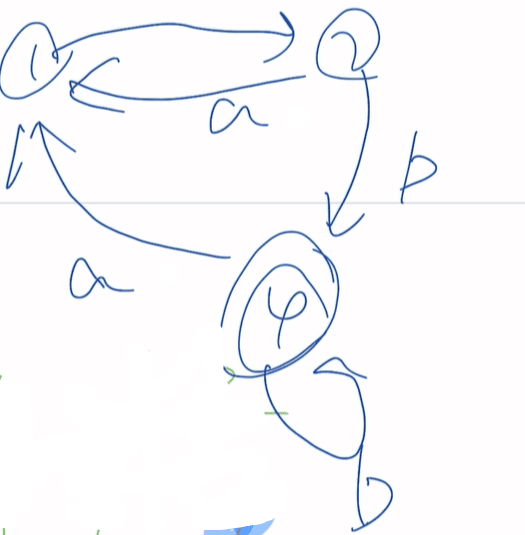
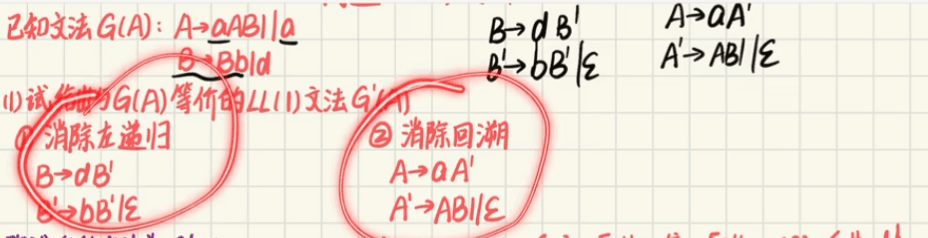
消除左递归
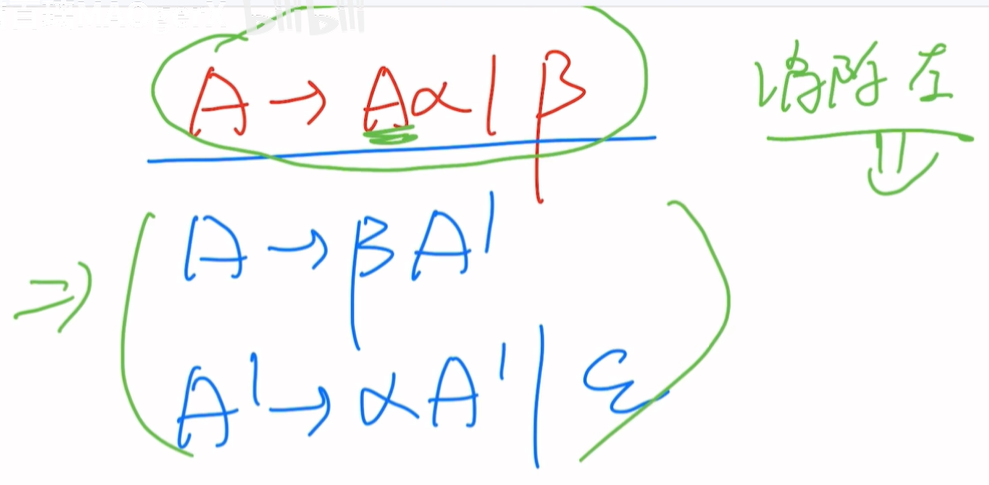
2条规则如上图
题一
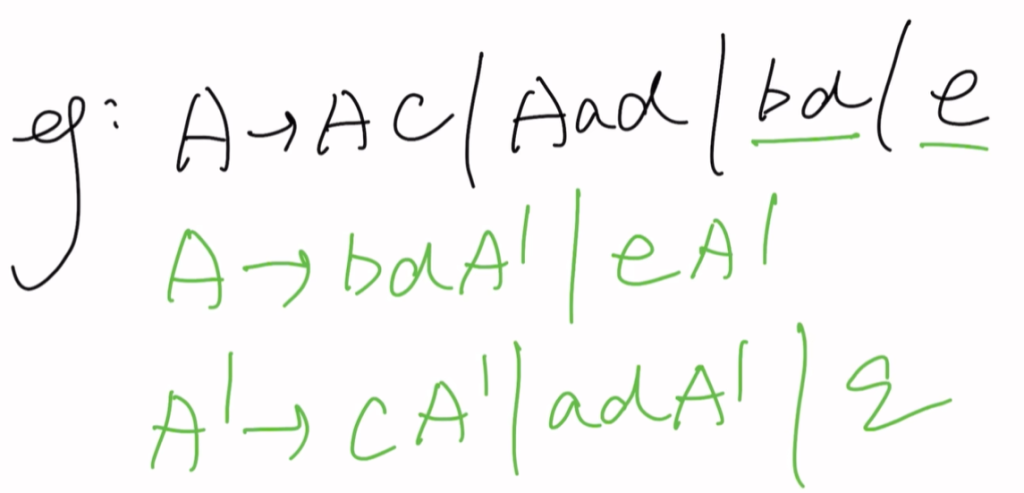
题二
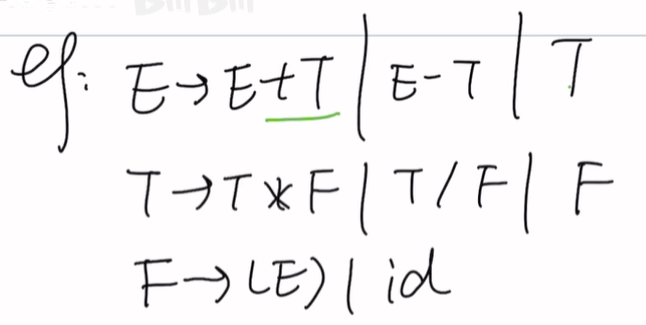

First集与Follow集
First集:看产生式左边第一个小写字母(终结符)eg:l,i,* …
Follow集:看右边
(1)开始符号集合加#
(2)A->αB 则Follow(B)=Follow(A) (B右边没有卫兵)
(3)A->αBβ(B后不为空)
- β小写,直接写
- β大写,Follow(B)= First(β)- ε
当:β-> ε,再来规则(2)

题一
First集:
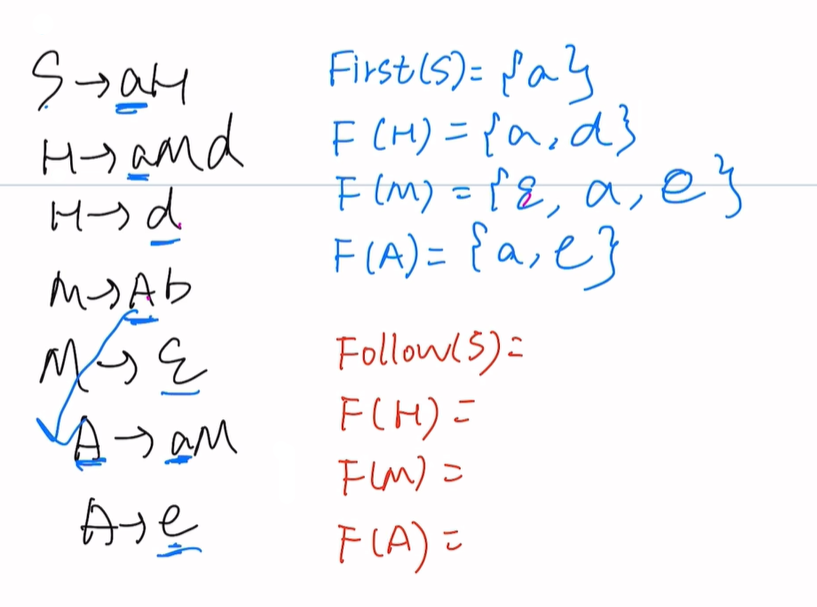
Follow集:
例如Follow(S):在右边找S,直接为空,但是S是开始符号所以要加#
注:第一个Follow就是开始符号,必须加#
Follow(H):在右边找H,即S->aH,H没有卫兵找规则(2)即Follow(H)=Follow(S)=#
Follow(M):在右边找M,有两个第一个中M右边卫兵是d为小写直接写,第二个M右边没卫兵Follow(M)=Follow(A),Follow(A)目前不知道,等我们算出来再补上去
接下来同理,过程略

题二
First集:
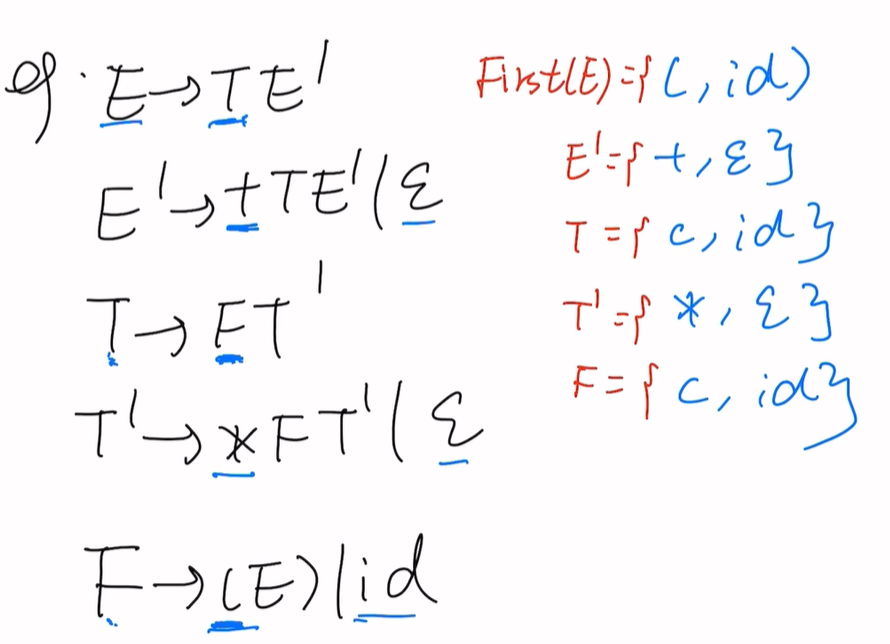
Follow集:
Follow(T):两种情况

第一种:T后边是E’(有卫兵且大写)按照规则Follow(T)=First(E’)-ε
即{+,ε}-ε = {+}
第二种:E’能推出空串ε,再来一次规则(2),即Follow(T)=Follow(E’)={#,)}
即{+,#,)}
Follow(F):两种情况
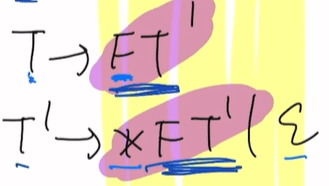
第一种:F后边是T’(有卫兵且大写)按照规则Follow(F)=First(T’)-ε
即{*,ε}-ε = {*}
第二种:T’能推出空串ε,再来一次规则(2),即Follow(F)=Follow(T’)={+,#,)}
即{*,+,#,)}
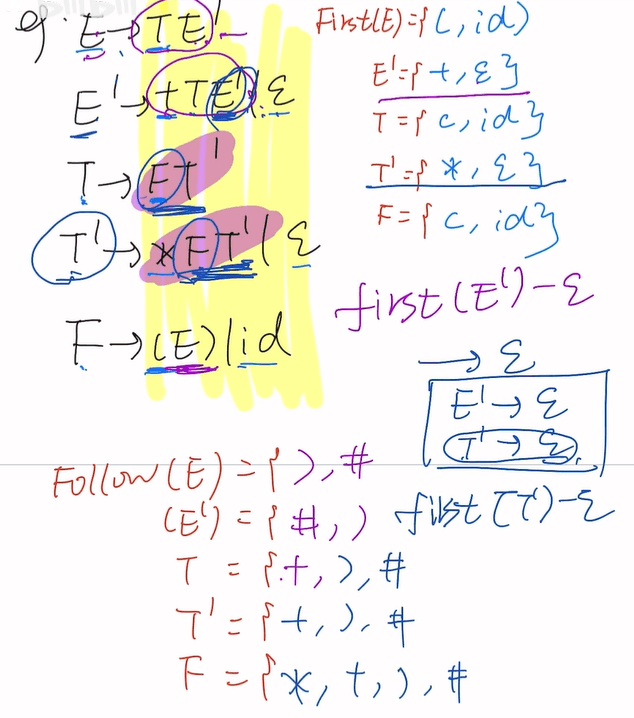
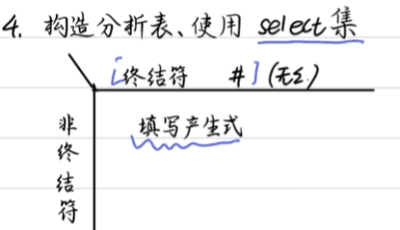
LL(1)文法的判断


判断LL(1)文法的步骤
1.消除左递归 ,消除公共左因子2.求出First集和Follow集 3.构建分析表(根据select集) 4.判断是否为LL(1):考试题目出了一定就是 5.给出输出串的分析过程(参考分析表)



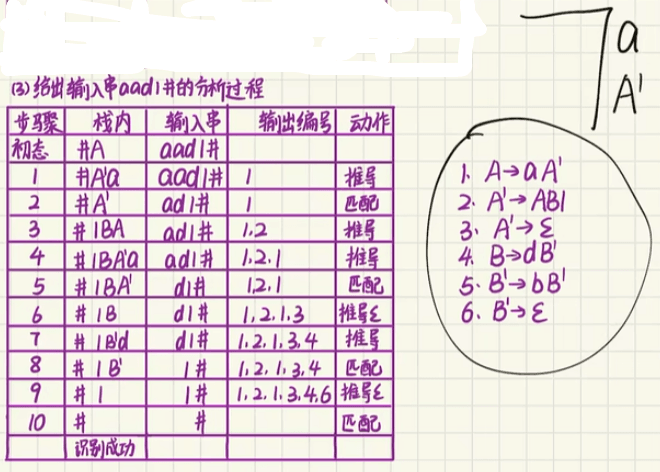
比如下面这道题:
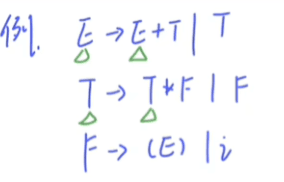
步骤一:消除左递归和回溯

步骤二:求First集和Follow集

步骤三:构建分析表
求select集根据select集填构建表

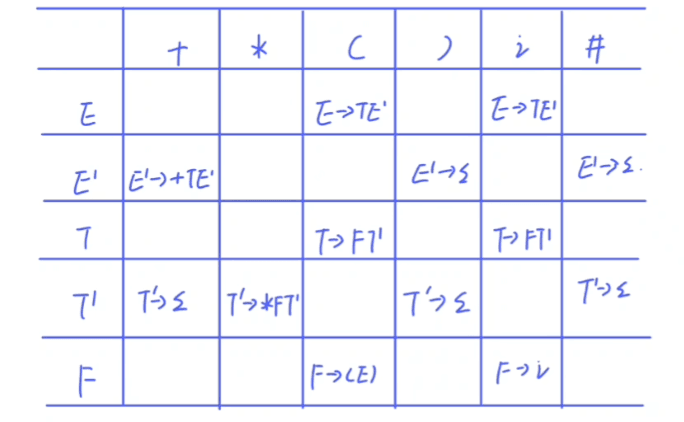
判断是否为LL(1)因为题只要出了就一定是,可写这部分可不写
步骤四:求题目中给出串的分析过程

根据文法构造算符优先关系表
1.先知道FIRSTVT和LASTVT
FIRSTVT看第一个,LASTVT看最后一个
FIRSTVT:
(1)第一个是终结符直接写 S->aB,a是终结符直接写
(2)左边是非终+终的形式,直接写右边的终,T->T,s T,即符合这一形式,写,
(3)P->Q Q的FIRSTVT进入P的FIRSTVT
LASTVT:
(1)最后一个是终结符直接写 (2)右边是终+非终的形式,直接写左边的终 与FIRSTVT对称
(3)一样


找出连在一起的终与非终的组合,比如:(E)

遵循3个规则:
终结符<FIRSTVT(非终结符)
LASTVT(非终结符)>终结符
终结符=终结符

由一个例子来理解
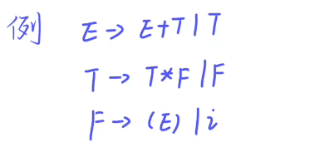
第一步

加上绿箭头所指的扩展文法,例如S->S+T|T, 则在上面加上S’->#S#
第二步
求出FIRSTVT和LASTVT
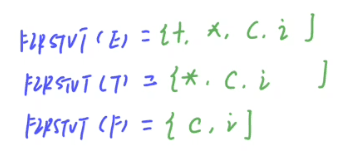
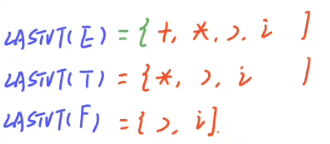
第三步
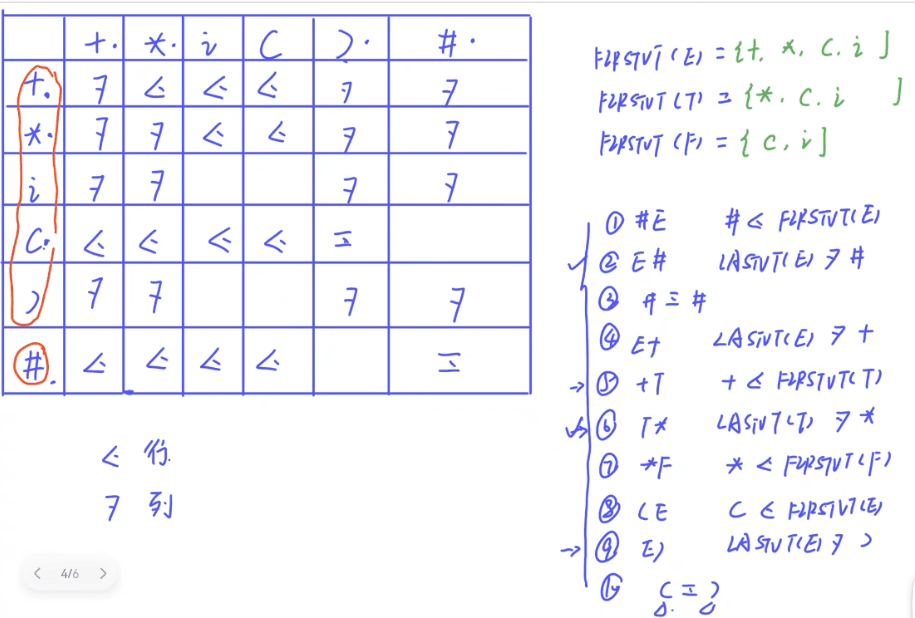
写算符优先表
第四步 算符优先分析过程
例题

第一步使用扩展文法

第二步 求FIRSTVT 和LASTVT

第三步构造优先表 遵循3个规则

先根据3个规则
例如E’->#E#,则有#<FIRSTVT(E),LASTVT(E)>#,#=#,下面同理
怎么填表?
例如:第一条,#<FIRSTVT(E),FIRSTVT(E)={; c a},因此在#这一行中;c a 这三列中填<
第四步 算符优先分析过程
比如(a*a)
非终结符和非终结符匹配,关系为<或者为=为入栈,关系为>为归约
入栈时把匹配的非终结符加进来即可
归约时把分析栈的终结符变成可以推导到它格式的子母(例如步骤三归约后,步骤四变把a变为H,因为只有H才能推导到a)
步骤十归约后为什么是H?
要找到谁能推导出(T)这样的格式:D->D(T)|H 不行,因为前面多了D,T->T*E|E不行,因为T和(T)格式不一样,H->a|(E)可以 因为(E)和 (T)一样
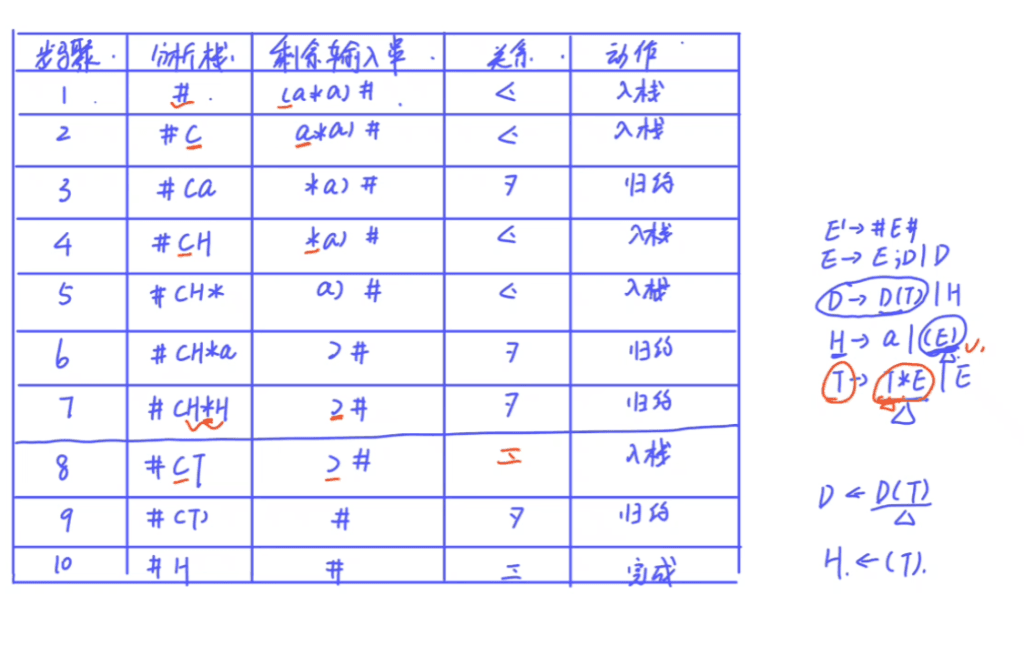
控制结构翻译成四元式
什么是四元式?

一遍扫描回填
例题一

例题二

例题三,if不嵌套
(1)如果a不为0,跳转到第七步(a不为0,if里的式子就为真直接跳到x=3)

例题四,if嵌套

写后缀表达式




表达式转换成三地址代码
什么是三地址码?

例如:
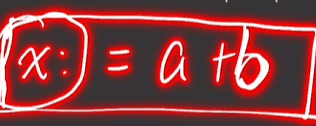
x: 为结果地址,a和b为操作数地址

题目中没写x:,结果就不写x:
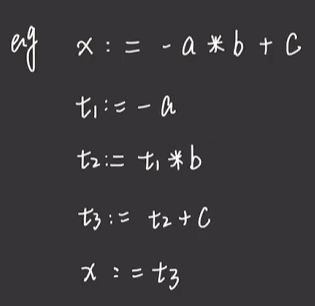
题目中有x:,最后的结果要赋值给x:
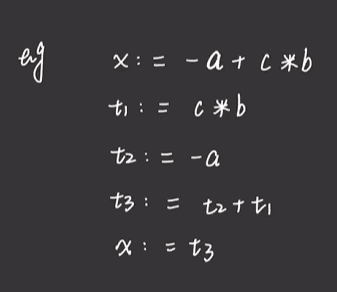

三地址码写汇编指令
三元式
直接三元式
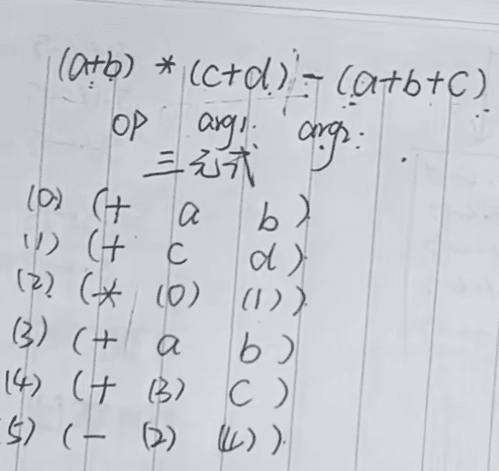
间接三元式

四元式
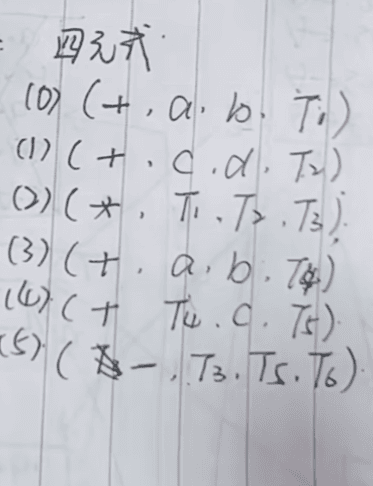
后缀表达式(逆波兰式)
a+b*(c+(d/e))
方法去括号,把运算符放括号外
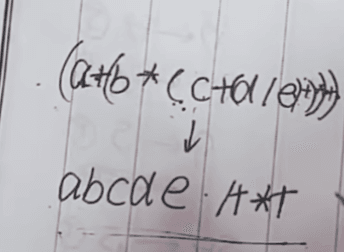
基本块的构造
由下往上画
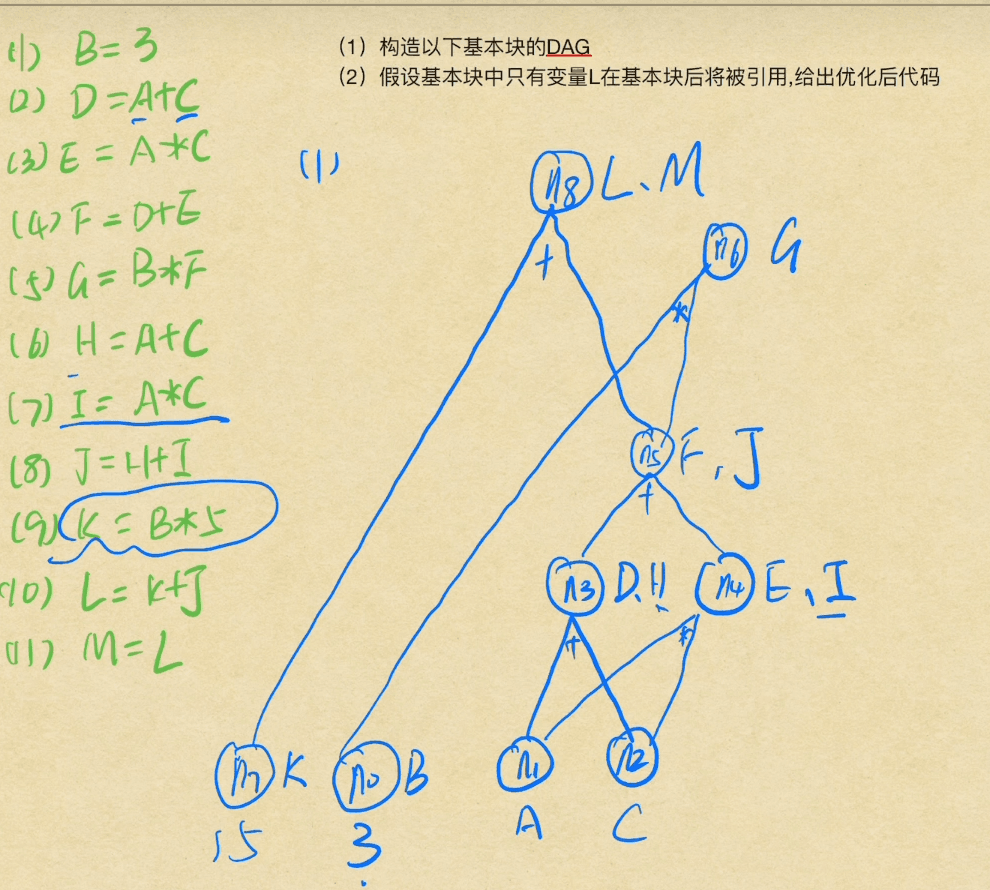
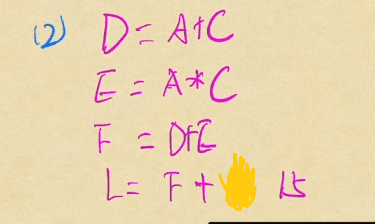
画出与L有关的线,取第一个字母全部列出来(由下往上)
入口语句的确定
知道哪些是入口?(3条规则)
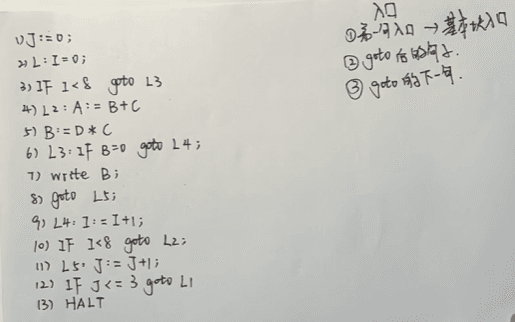
第一句必然是入口语句;goto跳转后的句子也是新的入口语句;goto的下一句也是入口语句(因为如果goto跳转失败会自动进入下一语句)
1.给入口语句画圈

2.给画圈的部分分基本块
分以下8块

并进行标号

3.列出基本块
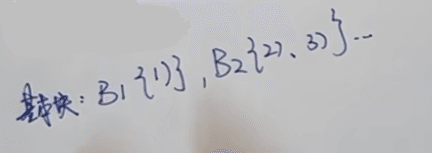
4.画出流程的顺序
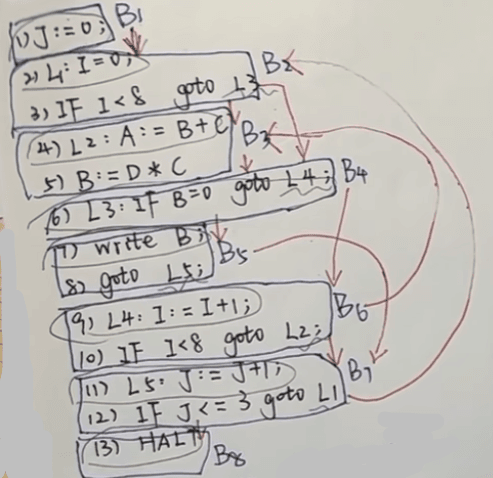
b1到b2,b2当跳转时到b4,不跳时b3,b3到b4,b4跳转时b6,不跳时b5,依次类推
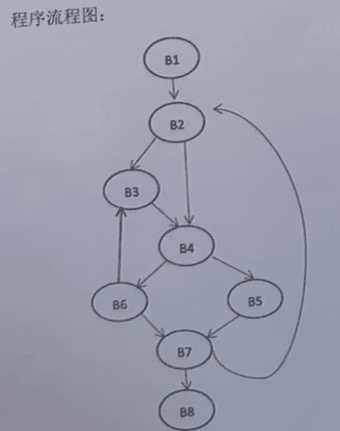
求节点集(只需找必经过的节点,未经过的取交集)
写法:先写必有的节点:开始与本身
中间写必经过的节点
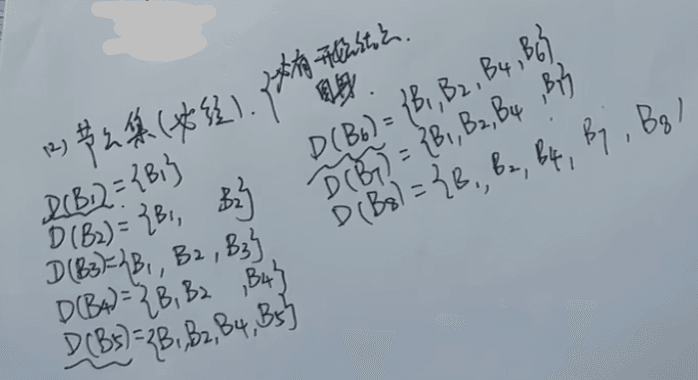
例如B4 D(B4)={B1, B2 ,B4} 因为B3不是必经过的节点
D(B5)={B1, B2,B4 ,B5} 必经过B4,所以必经过的节点里写B4的集合
D(B7)={B1, B2,B4 ,B7} 必经过B4,所以必经过的节点里写B4的集合
D(B8)={B1, B2,B4 ,B7,B8} 必经过B7,所以必经过的节点里写B7的集合